학습 모델을 만들때, 학습 데이터 양이 중요하다.
학습데이터양이 부족하더라도 이를 보강해주기 위한 Data Augmentation이라는 방법이 있다.
이 내용에 대해 살펴보겠다.
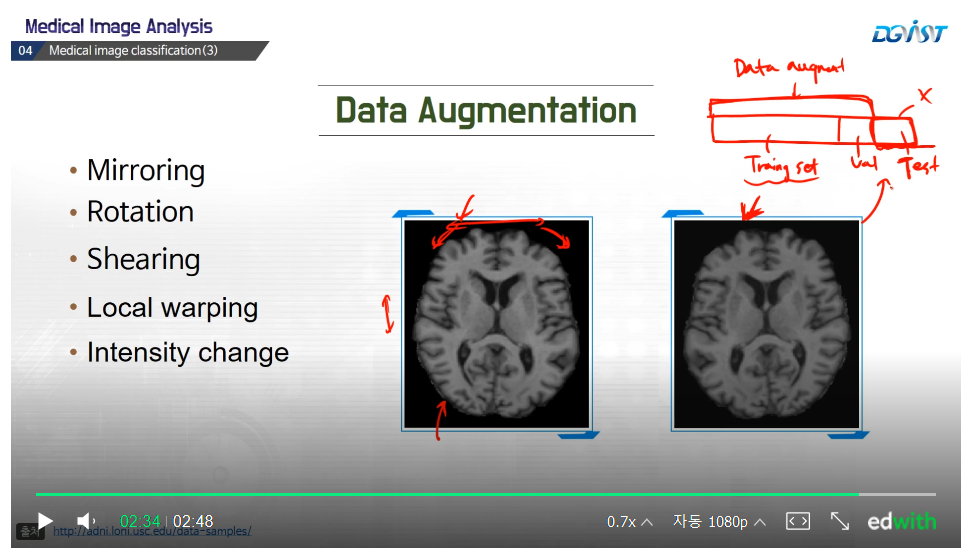
위의 그림은,
왼쪽이 원래 영상이고, 오른쪽에 있는 것이 밀러링 한 영상이다.
뇌 영상의 경우, 좌우 뒤집어도 새로운 brain 영상이로 생각 할 수 있다.
이처럼 플립한 영상을 트레이닝 데이터로 활용할 수 있다.
비슷한 방식으로 영상을 약간 rotate한 뒤,
그 영상을 training 데이터로 이용할 수 있다.
(물론 180도로 바꾸면 이상하지만, 이상하지 않은 범위 내에서 각도를 rotation할 수 있다.)
마찬가지로 영상을 약간 기울여서 새로운 영상 만들 수 있다.
로컬하게 특정지역만 조금씩 변화를 시켜서 새로운 영상을 만들 수도 있다.
역시 비슷하게,
영상이 어둡다면 좀 더 밝게해서 학습데이터에 넣을 수 있고,
또는 좀더 어둡게 해서 다양한 영상 만들어학습데이터로 사용할 수 있다.
보통 Data Augmentation를 트레이닝 데이터에 적용하게된다.
(트레이닝 set, validation set test set 중 트레이닝 셋)
테스트 할때는 학습된 모델을 그대로 적용한다.
test set에는 Data Augmentation을 하지 않는다.
실제 generation, augmented되는 영상들이 실제 test데이터의 distribution을 커버해주면 커버해줄수록
모델의 성능이 높아진다.
하지만 generation되는 것이 실제 test와 다른 경우에는 효과가 없을 수도 있다.
의료영상 분류문제의 경우 데이터 수가 적은 경우가 많기 때문에,
Data Augmentation했을때 성능이 좋아지는 경우가 종종있다.
'Deep learning' 카테고리의 다른 글
| 5-1. Feature selection using L1 regularization (0) | 2020.12.07 |
|---|---|
| 4-7. Evaluation of classification model (Multi-label) (0) | 2020.11.11 |
| 4-6. Evaluation of classification model (0) | 2020.11.05 |
| 4-4. Transfer Learning (0) | 2020.11.05 |
| 4-3. Overfitting / Regularization (0) | 2020.11.02 |
| 4-2. Validation (0) | 2020.11.02 |
| 4-1. Overall procedure (0) | 2020.10.28 |



