High-Resolution Image Synthesis with Latent Diffusion Models
https://arxiv.org/pdf/2112.10752
Abstract
오토인코더의 잠재 공간(latent space)내에서 확산 모델 훈련하여 연산량 감소
아키텍처에 어텐션 레이어 도입하여 텍스트/바운딩 박스 같은 조건 반영 가능
1. Introduction
자기회귀트랜스포모 모델 : 연상량 큼
GAN : 다중 분포로 확장이 어려움
확산모델 : 위 단점없음
확산 모델의 장점과 단점(연산량)
다음 단계로 개선(두번의 압축(지각적 압축, 생성모델의 의미적 압축(조건부 클래스, 바운딩박스 등))
2. Related Work
기존 생성 모델(GAN, VAE, ARM)의 한계를 극복하기 위해, 잠재 이미지 공간(latent image space)에서 자기회귀 모델(ARMs)을 학습하는 방식을 채택
기존 확산 모델(DM)은 픽셀 공간에서 학습하면 연산량이 너무 크므로 Stable Diffusion(LDMs)은 원본 픽셀 공간이 아니라, 압축된 잠재 공간에서 확산 모델을 학습하여 연산량을 줄이고 효율성을 높인다.
자기회귀 모델(ARM, Autoregressive Models) 훈련을 원활하게 하기 위해서는 높은 압축율(compression rate)이 필요필요하며, 이 과정에서 수십억 개의 매개변수(trainable parameters)가 추가되면서 모델의 성능이 제한된다.
반대로, 압축율을 낮추면 계산 비용이 급증하는 문제가 발생한다.
우리의 접근 방식(LDMs, 잠재 확산 모델)은 컨볼루션(convolutional) 기반 백본을 활용하여, 고차원 잠재 공간으로 확장할 때 기존 방법에서 발생하는 성능과 계산 비용 간의 트레이드오프(trade-off)를 피할 수 있다.
따라서, 우리는 최적의 압축 수준(compression level)을 자유롭게 선택할 수 있으며,
첫 번째 단계에서 강력한 표현력을 학습하면서도, 생성 확산 모델에 과도한 지각적 압축(perceptual compression) 부담을 주지 않으면서 고품질 재구성(high-fidelity reconstructions)을 보장할 수 있다.
3. Method
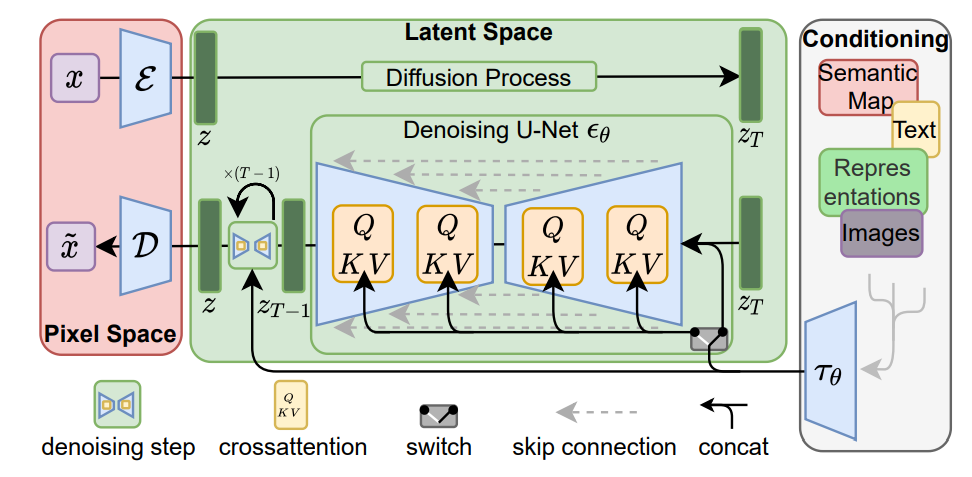
Stable Diffusion(LDMs)은 압축과정과 생성과정을 명확하게 분리한다.
오토인코딩(autoencoding) 모델을 사용하여, 원본 이미지 공간과 지각적으로 동등하지만 계산 복잡도는 훨씬 낮은 잠재 공간(latent space)을 학습한다.
샘플링이 저차원 공간에서 수행되어 연산량 감소.
UNet의 특성을 활용하여 과도한 압축 없이도 효과적인 학습 가능.
잠재 공간을 활용한 다양한 생성 모델 및 CLIP 기반 이미지 합성 등 추가 응용 가능.
3.1. Perceptual Image Compression
지각적 손실(perceptual loss)과 패치 기반(patch-based) 적대적 목표(adversarial objective)를 결합하여 훈련된 오토인코더(autoencoder)로 구성된다.
이 접근법은 로컬(realism, 현실감)을 강화하여 재구성이 이미지 매니폴드(image manifold) 내에 있도록 보장하며, L2 또는 L1 손실(pure pixel-space losses)만 사용할 경우 발생하는 블러(bluriness, 흐림) 문제를 방지한다.
잠재 공간(latent space)의 분산이 과도하게 커지는 것을 방지하기 위해, 방법1)잠재 벡터가 표준 정규 분포(standard normal distribution)를 따르도록 하는 KL-패널티(KL-penalty)를 추가하거나 방법2)디코더 내부에 벡터 양자화(Vector Quantization, VQ) 레이어를 추가하는 방식이다.(KL정규화, VQ정규화 사용)
이전 연구들은 잠재 공간 z의 분포를 자기회귀적(autoregressive)으로 모델링하기 위해 1D 순서를 강제로 부여했는데, 본 연구는 2D 형태의 잠재 공간 사용
3.2. Latent Diffusion Models
[Diffusion Models]
각 시간 단계(t)에서 디노이징 오토인코더처럼 동작하며,
노이즈가 추가된 입력 x_t에서 원래 노이즈 e을 예측하는 방식으로 학습된다.
손실 함수는 모델이 예측한 노이즈와 실제 노이즈 간의 차이를 최소화하는 방식(MSE, Mean Squared Error)으로 설계된다.
압축된 잠재공간은 확률 기반 생성 모델에 더 적합하다. 그 이유는 1.데이터의 중요한 의미적 요소(semantic bits)에 집중할 수 있으며, 2.저차원 공간에서 학습하므로 연산적으로 훨씬 더 효율적이기 때문이다.
[Generative Modeling of Latent Representations]
전방향(노이즈 추가 과정)은 사전 정의된 수식을 따르므로 학습이 필요 없음.
원본 이미지 x를 인코더에 통과시키고, 정해진 수식을 적용하면 z_t를 쉽게 얻을 수 있음.
인코더 E가 z_t를 추출하고, 샘플링 후 단 한 번의 디코더 D통과로 이미지를 생성할 수 있다.
3.3. Conditioning Mechanisms
확산 모델(DMs)도 원칙적으로 조건부 확률 분포 p(z∣y) 를 모델링할 수 있다.
조건부(conditioned) 디노이징 오토인코더 𝜖𝜃(𝑧𝑡,𝑡,𝑦)를 사용하여
텍스트(text), 의미적 지도(semantic maps), 이미지 변환(image-to-image translation) 등의 입력
y 를 기반으로 이미지 합성 과정을 제어할 수 있다.
UNet 백본(backbone)에 크로스 어텐션(cross-attention) 메커니즘을 추가하여, 확산 모델을 보다 유연한 조건부 이미지 생성기로 변환한다.
크로스 어텐션은 다양한 입력 모달리티(input modalities)를 학습하는 데 효과적인 방법이다.
입력 y 를 중간 표현(intermediate representation) 𝜏𝜃(𝑦)로 변환하는 도메인 특화 인코더(domain-specific encoder) 𝜏𝜃를 도입했다.
이 중간 표현은 크로스 어텐션 층을 통해 UNet의 중간 레이어에 매핑된다.
4. Experiments
Stable Diffusion(LDMs)은 기존 픽셀 기반 확산 모델보다 계산적으로 효율적이며, 더 빠르고 유연한 이미지 생성을 가능하게 함.
VQ-정규화된 잠재 공간을 사용할 경우 샘플 품질이 더 향상될 수 있지만, 재구성 성능은 연속형 모델보다 약간 떨어질 수 있음.
4.1. On Perceptual Compression Tradeoffs
다운샘플링 비율f에 따른 성능 차이 분석
f값이 작으면(예: LDM-1,2) → 훈련 속도가 느려짐.
f값이 너무 크면(예: LDM-16,32) → 압축 과정에서 정보가 손실되어 품질이 정체됨.
LDM-{4-8}이 가장 적절한 균형을 이루며, 높은 품질과 빠른 샘플링 속도를 제공함.
'Deep learning > 논문 리뷰' 카테고리의 다른 글
| CLIP(Contrastive Language-Image Pre-training) 논문 리뷰 (0) | 2025.02.09 |
|---|
