의료영상 분류를 수행할 때, demographic scores를 같이 고려해줄 필요가 있다.
영상과 demographic scores가 모두 있을 때, 분류를 어떻게 수행할 수 있을지 살펴보자

먼저 brain MR classification 문제에 대해 살펴보자
brain change는 다양한 factor에 의해 변할 수 있다.
표에는 나이, 성별, 영상으로 얻은 feature가 있다.
이전시간에 freesurfer를 이용하게 되면 volume을 얻을 수 있다고 했는데... 그것으로 예를 들어보자.
특정 feature(feature3처럼)는 질환에 대해 별 차이가 없는 것을 확인 할 수있다.
하지만 feature2처럼 AD에서는 항상 아주크게나타난다.
이런 feature있으면 classification에 유리하겠지만 이런 경우 아주드물다.
보통 feature1과 같은 경우가 많이 나타난다.
즉 모호한 경우이다.
feature1은 Normal, AD 둘다에서도 어느정도 큰 숫자를 가진다.
하지만 normal에대해서는 age가 많은 subject이다.
AD인 경우에는 나이가 적음에도 feature1 부위가 크다.
그래서 나이에 따라서 특정 feature들이 변화할 수 있다는 점(, gender에 따라 변할수도 있고)
여기서는 age와 gender에대해서만 나왔지만 사실 다양한 Demographic 요소가 더 존재한다.
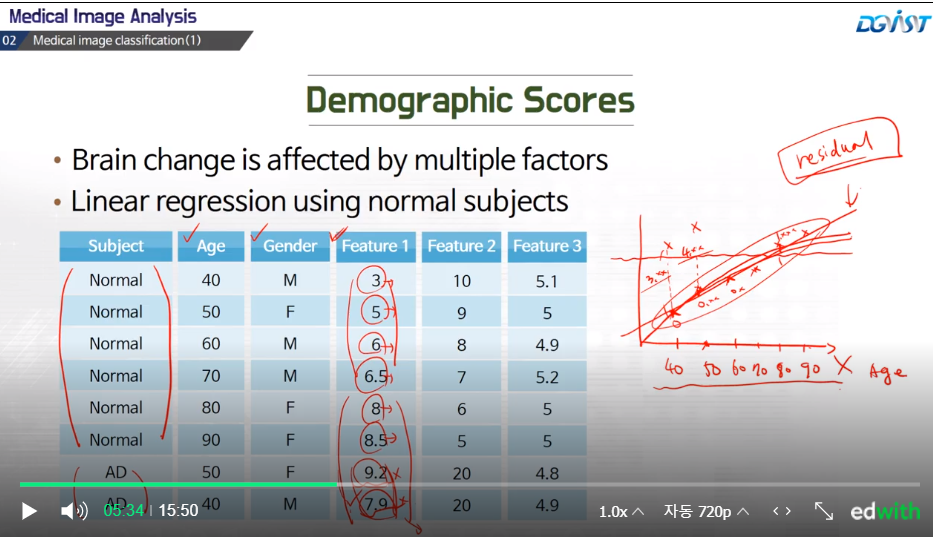
그래서 이런 것들을 보상해주기 위한 방법으로 linear regression 기법을 이용할 수 있다.
(결론 : age에 따른 feature1의 선형관계가 정규화되어 0에수렴되고 AD같은 특이한 케이스만 큰 값을 갖는다.)
예를들면 normal케이스에 대해서 linear regression 라인을 학습할 수 있다.
demographic factor(age, gender)가 우리의 feature가 되고 이 feature(feature1)가 실제로는 y가 된다.
그림 그래프로 설명하면 이해가 쉽다.
x축 : age
y축 : feature1
즉, 나이를 고려하지 않게 되면, 클래시파이어를 학습했을때는 상하로 구분이 될 것이다.
즉, y가 큰 서브젝트는 AD로 작으면 노멀로 판단할 수 잇을것
하지만 normal case를 바탕으로 linear regression 모델을 학습할 수 있다.
(1차직선 혹은 곡선 등으로)
이런식으로 linear regression 모델을 만들게 되면, 우리가 residual(잔여) 값을 구할수있다.
residual이라 하면 이런 feature를 normalization해준다고 생각하면 된다.
이 linear 라인에서 각 feature의 값을 빼주게 되면 정상 값은 차이가 거의 0에 가까울 것이다.
하지만 AD인 경우에는 residual 값이 상당히 클 것이다.
각 feature 값들을 residual값으로 normalization을 시켜줄수 있다.
그렇게 되면 이 값들이 거의 다 0으로 수렴을 하게 된다.
하지만 AD의 2개의 값만 커지게 된다.
이 feature가 지금의 값보다 좀 더 차별성 있는 피처가 된다.
그래서 linear regression 모델 정리를 해보면 아래와 같다.

residual 값을 계산하면 normal값에 대해서는 residual값이 상당히 작고,
AD인 경우에는 상당히 값이 크게 된다.
이것은 feature1에대한 그림이었는데 feature2,feature3 등 모든 n개의 feature에 대해서 같은 작업을 할 수 있다.
n개의 feature에 대해 다음과 같은 regression 모델 학습을 하고
이 feature들을 residual 값으로 업데이트를 해줄 수 있다.
지금은 Age에 대한 그래프를 그렸는데,
age뿐 아니라 gender, 다른 demographic feature에 대해서 같은 작업(보상)해줄 수 있다.
이런 보상들을 먼저 해준 뒤, 보상된 feature들을 바탕으로 classification 했을 때
질환 classification 성능이 높아지는 경우가 꽤 많이 있다.
그럼 전체과정에 대해 다시한번 정리 해보자

training할때는
- 여러image들이 있고 그에 따른
- demographic scores(D.S)가 있다.
트레닝 할때는 - 레이블도 가지고 있다.
이렇게 3가지 가지고 있다.
1. feature extractor
보통 이미지에서 이미지사이즈가 너무 크기때문에 feature를 뽑아준다.
feature extractor를 이용해서 feature를 뽑아주게 된다.
그럼 feature가 나오게 되고
demographic score를 가지고 와서
2. feature와 D.S를 이용해서 linear regression 학습가능하다.
이건 feature들을 normalization 하려고 하는 것이다.
residual을 구하면 normalization된 feature를 구할 수 있다.
age에 대한 normalization 된 feature라던지 성별이라던지..
3. 최종 만든 feature들과 lable을 고려해서 classifier를 만든다.
classifier에는 logistic regression, neural network, deep neural network 사용할 수도 있다.
테스트 과정을 살펴보면
1. 이미지 들어오고
데모그래픽 스코어를 알고있다고 가정한다.
실제로 병원에 환자오면 영상 물론 취득하지만, 데모그래픽 스코어도 알 수 있다.
2. 이렇게 얻은 영상을 분석할때, traing과 비슷한 과정을 거친다.
training때와 같은 feature extractor 사용해서 feature 뽑을 수 있고,
D.S 가지고와서 linear regression에 넣어주면
residual 구할 수 있고
어느정도 feature들이 라인에 normalization 된다.
여기서는 label이 없다.
3. 이 normalize된 feature들을 classifier에 넣어주게되고
그러면 classifier가 최종 lable을 prediction 해주게 된다.
classification 해주기 위해서 마지막 3. classifier 작업은 꼭 필요한 작업니다.
이것은 일반적인 이미지를 classification 하거나 medical 이미지들 prediction하거나 꼭 필요한 단계이다.
하지만 2. linear regressor 스텝은 D.S를 효율적으로 이용하기 위해 수행하는 스텝이다.
그래서 medical이미지에만 보통 이미지분석/분류할때 사용이 되는 부분이다.
1. feature extractor부분은 의료영상이 크기때문에 거기서 유의미한 피처를 뽑기위해 활용이 된다.
하지만 보통 이미지에서도 중요한 feature들을 먼저 뽑아서 그 feature들을 바탕으로 분류하는 경우도 꽤 있다.
만약 D.S가 없는 상황 고려해보자
없다면 2. linear regressor 스텝을 사용하지 않아도 된다.
1. feature 추출하고 추출된 feature바탕으로 바로 3. classifier 학습할 수 있다.
최근 딥러닝 기법에서는 사실 1. feature extractor 부분이 생략된다.(추후설명)
즉 이미지로부터 바로 레이블을 classifier 하도록 학습가능하다
이전 차시에서 살펴봤던,
dog을 classifier하는 문제에서도 영상을 바로 logistic regression에 넣을 수 있엇다.
이런 경우도 바로 feature를 뽑지 않는 경우이다.
만일 트레이닝 과정에서 바로 classifier로 갔다면
테스트과정에서도 그렇게 해야한다.
여기서 한가지 의문이 들 수 있다.

우리가 구분하고자하는 레이블인 노말인지 AD인지이다.
feature1,2,3은 영상으로부터 나온 피처
사실 D.S도 하나의 feature로 쓸 수 있다. (feature4, feature5라고 볼 수 있다.)
5개의 피처를 가지고 classifier를 만들 수 있다.
3개는 이미지feature이고 2개는 DS로 feature이용하는 방법이다.
이렇게 쓰기 위해서는 샘플이 많아야한다.
다양한 age를 잘 커버할수 있는 샘플 수, 즉 m이 많아야하고
gender들을 잘 포함하고 있는 데이터가 많아야한다.
보통 데이터가 많은 경우에는 linear regression으로 feature를 normalization 하는 방법을 보통 쓰지 않는다.
하지만 실험하다보면 matched data
데이터를 많이 구해서 10,000장 있다 하더라도 이중에서 노말과 AD 비교하는 연구 수행할 때
노말에 속한 사람들의 age분포와 ad그룹에 속한 사람들의 age 분포가 비슷해야하고
gender분포도 비슷해야한다.
이런 다양한 요소 맞추다보면 사실상 쓸수있는 데이터수가 줄어들게 된다.
이렇게 줄어들게 되면 다양한 케이스를 커버할 수 있는 classifier를 만들기 어려워진다.
보통 작은 데이터로 실험 진행하는 경우에
DS에 따른 영향을 먼저 없애고
없앤 feature 즉, normalize된 feature로 분류를 수행하는 경우가 많이 있다.
하지만 다시 말하지만
데이터가 아주 많다면 이런 D.S를 하나의 feature로 넣는 식으로 하는 연구를 진행해도 문제 없다.
여기까지 DS가 주어졌을때 의료영상 분류 어떻게 수행할 수 있는지 알아봤다.
다음주차에서는 최근 분류문제에 좋은 성능을 내고있는 딥러닝 기법들에 대해 좀더 알아보자.
'Deep learning' 카테고리의 다른 글
| 3-3. Convolutional Neural Network (CNN) (0) | 2020.08.20 |
|---|---|
| 3-2. Convolution (0) | 2020.08.19 |
| 3-1. Property of Deep Neural Network (0) | 2020.08.15 |
| 2-6.Medical image classification (0) | 2020.08.08 |
| 2-5.Image Classification (0) | 2020.08.08 |
| 2-4.Neural Network (0) | 2020.08.06 |
| 2-3. Logistic Regression (0) | 2020.07.28 |



