본 차시에서는 CNN(convolutional neural network)이
1. 어떻게 구성,
2. 어떻게 동작하는지 알아보자

일반적으로 CNN은
1. convolutional layer
2. pooling layer
3. fully connected layer
로 구성되어있다.
먼저 이 레이어들 하나하나 살펴보자.
1. convolutional layer은 앞 수업에서 설명했던것처럼,
영상 주어지면 필터링하는 과정과 같다.
보통 필터를 한개만 사용하지 않고, 다른 필터를 학습할 수도있다.
그럼 또, 이 필터에 대한 다른 값이 나온다.
마찬가지로 이 과정들(필터 여러개 사용하는)을 반복할 수 있다.
최종으로, 4x4 영상을 3개 얻을 수 있다.
이것을 feature map 이라고 한다.
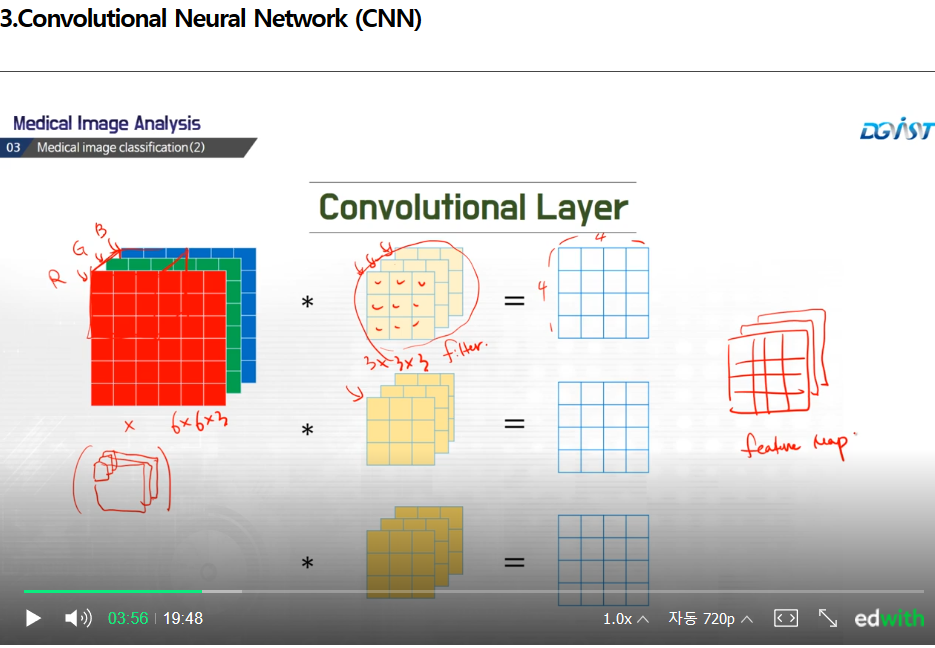
실제, 영상 살펴보면,
영상은 3개 채널로 구성되어있다. (R,G,B)
이런 경우, 그냥 3by3필터링하면,
채널마다 각각하면
최종결과로 4by4로 영상 3개가 나온다.
그러나 이런식으로 필터링 하지 않고
보통 CNN에서는 필터자체도 3개의 채널로 만든다.
2D에서는 3by3으로 9개만 학습했다면,
여기서는 총 9*3=27개의 숫자를 학습해야한다.
여기서의 필터는 3x3x3이다.
최종 결과는 4x4이다.(차원별(정육면체 같은위치끼리)로 계산한다.)
역시 마찬가지로 다른 필터도 학습가능하다
반복적으로 값을 얻을 수 있다.
이전 슬라이드와 마찬가지로 4x4영상 3개를 얻을 수 있고
이것이 피처맵이 된다.

그럼 이 4x4맵 3채널이 있는데,
다시 필터 학습해보자.
3x3필터링을 수행해보자.
이런 필터들을 또 여러개 이용하면, 2x2영상이 3개만들어지는 피처맵을 얻을 수 있다.

그리고 convolution할때 stride를 조절할 수 있다.
상 : 원래는 한칸씩 이동(s=1)해서 수행하여, 결과로 4x4 영상이 나온다.
이 경우에는 stride가 1인 경우이다.
하지만 s=2로 할 수 있다.
하 : 좌우, 상하 두칸이동하여 convolution수행한다.(칸이 모자라면 버린다.)
결과로 2x2영상을 얻는다.
스트라이드, 필터 개수(몇가지 필터 쓸건지:O, 필터채널 이야기하는 것 아님)는 유저가 먼저 지정을 해주는 하이퍼파라미터이다.
필터안의 숫자는 파라미터라고 부르고,
이 숫자들은 학습이 되는, 업데이트가 되는 파라미터이다.

패딩에 대해 공부해보자.
보통 convolution 수행하게 되면, 원래영상사이즈보다 아웃풋 영상사이즈가 작아지게 된다.
(아까처럼, s=1로 했을때, 결과가 4x4로 줄어듬)
그러나 패딩쓰게 되면, 사이즈를 유지할 수 있다.
패딩은 이미지 외곽부분에 라인들을 추가하여 값들을 넣어준다.
convolution수행할때 외곽 추과된 라인부터 수행이 되므로,
원본이미지와 같은 사이즈의 영상을 최종결과로 얻을 수 있다.
그럼 추가되는 값들은 어떻게 정의할까?
1. 0값을 넣어주거나,
2. 가장 가까운 픽셀의 값으로 채운뒤 필터링 할 수도 있다.
3. 혹은 원본 영상을 그대로 옆에 복사해서 붙인다.(ex 추가되는 가장 앞줄에는 가장 마지막픽셀값이 추가된다.)
이런식으로 다양한 패딩방법이 존재한다.
패딩한 뒤 convolution하게 되면 사이즈 유지 가능하다.
여기까지가 convolutional layer에 대한 설명이었다.
다음슬라이드에서는 pooling layer에 대해 살펴볼것

pooling layer는 이미지 사이즈를 줄여주는 레이어이다.
(물론 이 과정에서, 스트라이드나 패딩을 함께 이용하여 줄이지 않을 수도 있다.)
그러나 보통은 영상을 줄여주는 레이어이다.
예를들면 풀링은 원본이미지 내의 정해진 사이즈 중의 한 숫자를 가져오는 작업을 한다.
보통 max pooling을 많이 사용한다.(정해진 사이즈 내 가장 큰값 가져옴)
풀링방법도 정의하기 나름이다.
예로, average풀링(정해진 사이즈 내 평균값)도 있다.
풀링레이어의 이미를 살펴보면
보통, 맥스풀링이나 애버리지 풀링 많이 사용한다.
(그중 맥스풀링 많이 쓴다.)
이유는
로컬한 부분에서 가장 튀는 값을 가져왔을때...
convolution layer->pooling->convolution layer->pooling
이런식으로 넘어가서 최종적으로 프레딕션하게되는데
풀링과정에서 로컬한 부분의 중요한 특징들이 유지가 되도록 하면
classification 성능을 높이는데 도움이 된다는 연구가 있기에 맥스풀링 주로 사용.
(물론 애버리지풀링도 많이 사용한다.)
다음은 fully connected layer에 대해 살펴볼것.

convolution layer와 pooling layer를 통과하다보면,
어느순간 피처맵이 충분히 작아지게 된다.
이때 보통 fully connected layer를 사용한다.
원리를 살펴보면,
4x4피처맵3개
각 하나하나의 값을 하나의 숫자로 본다.
deep neural network에서 봤던것처럼
모든 값들이 다 연결이되고,(4*4*3 + bias1)
거기마다 각각의 파라미터(w1, w2, w3...)가 있다.
파라미터는 4*4*3=48에 바이어스텀1해서 총 49개.
각 노드마다 이 작업이 반복된다.
두번째노드에서도 49개의 파라미터가 생기게된다.
이렇게 전체 다를 연결하는데 이를 fully connected layer라고 말한다.
그래서 최종적으로 숫자를 줄여서 6개있을때 최종 프레딕션하겠다.
사실 이 구조는 앞에서 봤던 neural network 구조이다.
그럼 전체 구조를 한번 살펴보자.
CNN의 모든 컴포넌트들을 살펴봤고,
이 컴포넌트들을 이용해서 어떻게 만들수 있는지 다음슬라이드에서 봐보자.

1. 영상들어오면 정의해준 필터링을 수행한다.
3x3 convolution으로 정의해줬으니 3x3의 필터를 쓸것이다.
색깔이 있으니 RGB영상이니 채널이 3개있을것이다.
하나의 필터는 27(3*3*채널3)개 값을 가지고 있고
convolution하게되면 그 값에의해 피처맵이 나오게된다.
다른 두번째 필터 또 쓰면, 필터정의하는데 27개의 값이 필요할것이고,
그럼 두번째 피처맵이 나올것이다.
이런식으로 여러개 필터쓰면(여기서는 9개의 피처맵이 나왔으니 9개의 필터를 쓴것이다.)
2. 그다음 보통 convolution이후 pooling을 사용한다.
pooling 사용해서 영역에서 중요한 신호들을 가지고 오는 풀링작업을 수행한다.
풀링 할때는 사이즈가 반으로 줄어든다.
맥스풀링하던지, 애버리지 풀링하던지.
그렇기에 여기서는 파라미터가 없다.
3. 다시 convolution수행
여기서는 다시 필터정의하는데 파라미터 필요하다.
3x3필터로 정의 되었고, 뎁스(채널수)가 9개.
그렇기때문에 필터사이즈는 3x3x9가 된다.
3x3x9필터 하나에 대해서 원본이미지(채널9개짜리) 전체로부터 하나의 피처맵이 나오게된다(필터하나에대해서).
그다음 또, 다른필터 2번째필터를 학습하면 피처맵 2번째것이 나온다.
이런 식으로 계속 반복해서, 필터수만큼 피처맵이 나온다.
4. 그다음 다시 풀링
5. 그다음 마지막 부분에서 fully connected layer를 사용하는데,
픽셀 2x2로 가정해보자.
각 픽셀 하나하나의 값들(2*2*20)이 모든 노드(15개)로 연결이 된다.
마지막에 최종판단을 내리는 fully connected layer이다.
최종적으로 두번째 fully connected layer에서 prediction 값이 나오고, prediction된 값(h)과 y값, 이 사이의 에러를 구하고
이 에러를 바탕으로 back propagation하게된다.
영상이 들어왔을때 이런 스텝, 필터들을 바탕으로 쭉 계산이 되서 결국 피처(fully connected layer의 노드)들이 추출이 된다(추출이 된 피처 : extracted feature).
최종 추출된 피처(extracted feature)을 바탕으로 classification이 되는 구조이다.
쭉 포워드 프로퍼게이션으로 프레딕션을 얻고
그다음 y값과 비교해서 derivative도함수 값을 구하고
각 필터의 파라미터값들을 백프로퍼게이션으로 업데이트 해준다.
테스트할때는 비슷하게
이미지 입력을 해주고(트레이닝시에 필터, 풀리 커넥티드 레이어의 모든 파라미터들 다 만들이져있음),
이 과정들 다시 쭉 거쳐서 프레딕션 값을 최종적으로 얻어낸다.
여기까지 CNN에 대해 알아봄.
다음차시에서는 좀더 advanced된 CNN구조들에 대해 살펴보자.
'Deep learning' 카테고리의 다른 글
| 3-6. CNN with demographic scores (0) | 2020.10.25 |
|---|---|
| 3-5. Advanced CNNs (ResNet, InceptionNet, DenseNet) (0) | 2020.10.05 |
| 3-4.Advanced CNNs (LeNet, AlexNet, VGG) (0) | 2020.09.15 |
| 3-2. Convolution (0) | 2020.08.19 |
| 3-1. Property of Deep Neural Network (0) | 2020.08.15 |
| 2-7. Classification with demographic scores (0) | 2020.08.09 |
| 2-6.Medical image classification (0) | 2020.08.08 |



